1. 예시 데이터와 목표 데이터

- 먼저 좌측의 X1, X2, X3 처럼 categorical variables 를 원핫인코딩을 통해 우측의 형태처럼 변경시키고자 한다.
- 이때는 pandas의 get_dummies() 혹은 scikit learn의 OneHotEncoder 를 사용할 수 있다.
2. pandas → get_dummies()
- 공식 레퍼런스 페이지: https://pandas.pydata.org/docs/reference/api/pandas.get_dummies.html
- get_dummies() 함수를 사용하는 법은 굉장히 쉽다.
간단하게 말하면 일단 object data type 인 컬럼을 확인하고, 그 컬럼들만 변경해준다.
아래의 과정을 참고하자.
# object 컬럼 확인
df.select_dtypes('object').head(3)
# object 컬럼명만 확인
cols_o = df.select_dtypes('object').columns.values
cols_o
# pandas get_dummies() 함수 이용
df_dummies = pd.get_dummies(data=df, columns=cols_o)
df_dummies
이렇게 쉽게 get_dummies() 함수를 통해서 인코딩할 수 있다. 하지만 train dataset 과 test dataset 이 분리되어 있는 데이터의 경우, 각각을 따로 get_dummies()를 해주게 되면 train dataset에 대한 encoding 결과와 동일하게 test dataset 이 인코딩 되지 않을 수 있다.
따라서 이런 경우에는 scikit learn의 OneHotEncoder를 이용해 주도록 한다.
3. scikit learn → OneHotEncoder
- 공식 레퍼런스 페이지: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.OneHotEncoder.html
- 사이킷런의 원핫인코딩은 판다스 get_dummies() 보다는 좀 더 조작이 필요하다.
인코딩 결과가 array 형태로 나오게 되며, 이를 다시 컬럼명도 맞춰주고 데이터프레임 형태로 만들어줘야 한다.
아래의 과정을 참고하자.
# scikit learn OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder(sparse=False)
arr_ohe = ohe.fit_transform(df[['X1', 'X2', 'X3']])
arr_ohe# 다른 방법
from sklearn.preprocessing import OneHotEncoder
ohe = OneHotEncoder()
arr_ohe2 = ohe.fit_transform(df[['X1', 'X2', 'X3']]).toarray()
arr_ohe2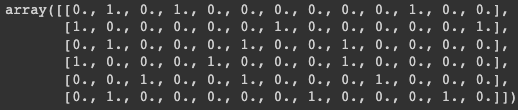
위에 두가지 방식을 적어두었지만, 테스트 결과 동일한 결과가 출력됨을 확인했다.
계속 과정을 진행해보겠다.
ohe.categories_
# 원래 데이터와 원핫인코딩된 데이터 concatenate
df_ohe = pd.DataFrame(arr_ohe2)
df_concat = pd.concat([df, df_ohe], axis=1)
df_concat
원핫인코딩 결과를 array 형태에서 dataframe 형태로 변경하고, 이를 원래 데이터와 결합하였다.
확인 결과, X1, X2, X3가 그대로 남아있으며, 새로 결합한 데이터의 컬럼명은 0~12로 설정되어 있어서 무엇을 의미하는지 모르기 때문에 추가 작업이 필요할 것임을 알 수 있다.
일단 원래 데이터에서 X1, X2, X3는 이제 필요하지 않기 때문에 다시 새로운 데이터프레임을 만들어주도록 한다.
# 인코딩 필요없는 컬럼만 새로 데이터프레임 생성
cols_o = df.select_dtypes('object').columns.values
df_not_objs = df.drop(columns = cols_o)
# concat: df_not_objs + df_ohe
df_concat2 = pd.concat([df_not_objs, df_ohe], axis=1)
df_concat2
이렇게 필요하지 않은 컬럼은 삭제한 상태로 데이터프레임을 생성하는 것이 더 좋다.
컬럼명을 제대로 변경해주기 위해서는 아래의 코드를 참고하자.
# 카테고리 컬럼명까지 포함한 df_ohe
ohe_cols = []
for i in range(len(ohe.categories_)):
ohe_cols += [f'cat{i}_' + col for col in ohe.categories_[i]]
df_ohe2 = pd.DataFrame(data=arr_ohe2, columns=ohe_cols)
df_ohe2
multiple variables 에 대해서 one hot encoding을 했기 때문에 이렇게 반복문으로 categories 리스트를 돌며 컬럼명을 생성해주고 이를 이용하여 데이터프레임을 생성하였다. 이렇게 생성한 데이터를 다시 원래 데이터와 결합시켜주면 된다.
pandas 의 get_dummies() 함수를 사용하는 법과, scikit learn 의 OneHotEncoder 를 사용하는 법을 확인하였다.
두 메소드간에 차이가 있기 때문에 이점에 유의하면서 사용해야하며, 크게 어렵지는 않으니 몇 번만 연습해보면 익숙해질 것 같다.
'[Python] 연습' 카테고리의 다른 글
| [python] 프로그래머스 신고결과받기 (0) | 2022.10.29 |
|---|---|
| [python] 프로그래머스 성격유형검사하기 (0) | 2022.10.28 |
| [python] 프로그래머스 큰 수 만들기 (0) | 2022.10.22 |
| [Python] 범주형 변수 처리 - dummy coding (0) | 2022.09.18 |
| Python을 활용한 AI 모델링 - 전처리 파트 (0) | 2022.09.11 |