Group by
데이터 분할(split) > operation 적용(applying) > 데이터 병합(combine)
> groupby 내부 함수 활용하기
>> 그룹 데이터에 적용 가능한 통계 함수(NaN은 제외하여 연산)
>> count: 데이터 개수
>> size: 집단별 크기
>> sum: 데이터의 합
>> mean, std, var: 평균, 표준편차, 분산
>> min, max: 최소, 최대값
> 복수 columns를 기준으로 grouping 하기
>> 통계함수를 적용한 결과는 multiindex를 갖는 DataFrame
# cust_class 와 sex_type으로 index를 정하고 이에따른 r3m_avg_bill_amt의 평균을 구하기
cust.groupby(['cust_class', 'sex_type']).mean()[['r3m_avg_bill_amt']]
pivot, pivot_table
DataFrame 형태를 변경하는 것(columns, row를 기준으로 데이터를 변형)
pivot > pandas.pivot(index, columns, values)

pivot table > pandas.pivot_table(index, columns, ...)
- pivot은 불가하고 pivot table은 가능한 경우
중복 값이 있는 경우
집계 처리가 필요한 경우
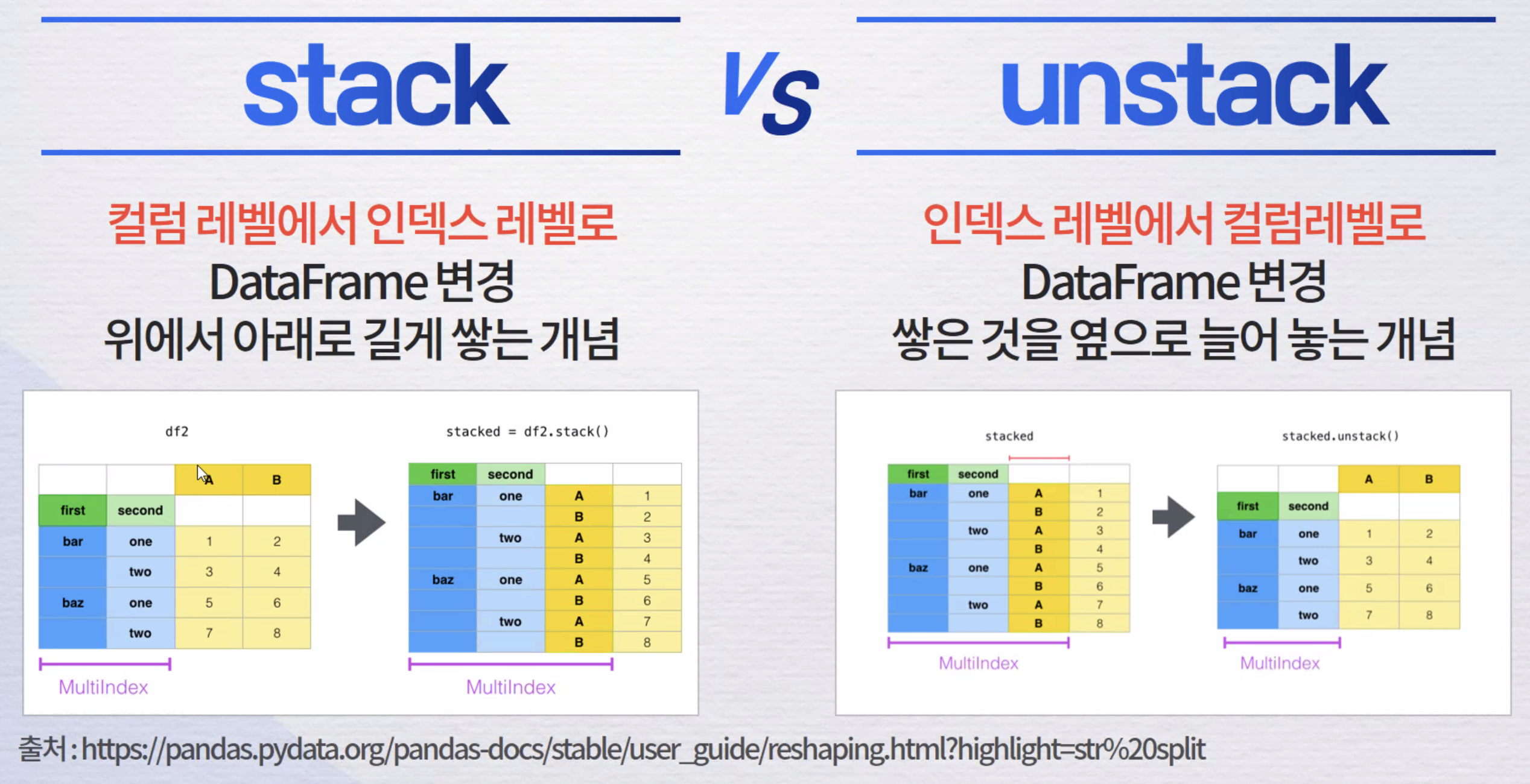
stack, unstack
DataFrame을 재구조화하기 위해서 사용
'[Python] 연습' 카테고리의 다른 글
| [Python] 목소리 음 높이 확인하기(Voice Pitch Tracker) (0) | 2022.08.16 |
|---|---|
| [AIFB] Pandas DataFrame (0) | 2022.08.14 |
| [AIFB] Python Basic (0) | 2022.08.12 |
| 텐서플로로 간단한 머신러닝 실습하기 (0) | 2022.07.11 |
| [Python] NumPy 배열 인덱싱, 슬라이싱 연습 (0) | 2022.07.07 |