이번 포스팅에서는 dplyr 패키지에서 두 데이터프레임의 열 병합과 행 병합에 대해서 다루도록 하겠다.
이전 1~3편에서 다루었던 내용을 요약하자면,
1) 데이터프레임에서 특정 조건에 맞는 행을 추출하고 싶다면 filter()함수를 사용하자.
2) 데이터프레임에서 특정 열만 추출하고 싶다면 select()함수를 사용하자.
3) 데이터프레임에서 오름차순 정렬은 arrange() 함수를, 내림차순 정렬은 arrange(desc()) 함수를 사용하자.
4) 데이터프레임에서 파생변수 추가는 mutate() 함수를 사용하자.
5) 특정 변수를 기준으로 데이터를 요약하고 싶다면 group_by() 함수와 summarise() 함수를 사용하자.
이번에도 Cereals 데이터를 사용할 것이다. (첨부파일)

Q. 두 개의 데이터프레임에서 공통된 열을 병합하고 싶을 떄는?
A. inner_join() / left_join() / right_join() / full_join() 함수를 사용하자.
단, 각 함수가 공통된 열을 병합한다는 것은 같지만 그 기준은 다르다는 것에 주의할 것.
각 함수의 이해를 위해 Cereals 데이터를 두 개의 데이터프레임으로 나눠보자.
cereal <- read.csv("Cereal.csv")
library(dplyr)
# cereal 데이터셋에서 일부 데이터만 추출
x <- cereal[1:9,c(1,2,3)]
y <- cereal[2:10,c(1,4,5,6)]| |
|
위 그림처럼 x 데이터와 y 데이터로 일부만 추출하였다.
두 데이터프레임에 'name'이라는 공통된 변수가 있고, 나머지 열은 다른 변수들이다.
또한 x에는 '100%_Bran' 제품이 있는데, y에는 해당 제품이 없고, 반대로 y에는 'Bran_Flakes'에 대한 데이터가 있지만 x에는 없다.
이제 이 두 데이터프레임을 합치려고 할 때, 제품명(name) 변수를 기준으로 병합하고 싶다면, 다음과 같이 사용할 수 있다.
# x랑 y 데이터프레임에서 'name' 칼럼을 기준으로 열을 병합
inner_join(x, y, by = 'name') # 공통적으로 존재하는 데이터에 대해서만 열을 병합
left_join(x, y, by = 'name') # left(좌)에 있는 x를 기준으로 / 없으면 NA
right_join(x, y, by = 'name') # right(우)에 있는 y를 기준으로 / 없으면 NA
full_join(x, y, by = 'name') # 두 데이터프레임에 존재하는 모두를 병합간단히 각 함수에 대해 설명하자면,
inner_join() 함수는 공통적으로 존재하는 데이터에 대해서만 열을 병합하기 때문에, 각 데이터프레임에 없는 제품은 결합되지 않는다.
left_join() 은 x 데이터프레임이 기준이라 y에 없는 데이터에 대해서는 NA로 표시되는 것을 볼 수 있다.
right_join() 은 y 데이터프레임 기준으로 병합해서 x에 없는 Bran_Flakes는 mfr, type 이 <NA> 다.
full_join()은 by = ~ 을 기준으로 다 병합한다. 그래서 한 쪽 데이터 프레임에만 있는 것도 결합한 결과가 나온 것을 볼 수 있다.
| |
|
| |
|
★ 예시문제1)
Cereal 데이터에서 제품명(name), 제조사(mfr), 제품 타입(type), 선반 진열 위치(shelf)에 대한 변수만 추출하여 새로운 데이터프레임을 생성하고, 또 다른 새로운 데이터프레임에는 shelf(열 이름)에 1, 2, 3을 입력, place(열 이름)에 'bottom', 'middle', 'top'을 입력하여 새로 생성하시오. 그 다음 이 두 개의 데이터프레임을 shelf를 기준으로 병합하시오.
예시답안)
ex1 <- cereal[, c("name",'mfr','type','shelf')]
ex2 <- data.frame(shelf = c(1, 2, 3),
place = c("bottom", "middle", "top"))
inner_join(ex1, ex2, by = 'shelf')
실행결과)
# 사실 ex1 <- cereal %>% select(name, mfr, type, shelf) 도 좋다.
Q. 두 개의 데이터프레임을 행으로 병합하고 싶다면?
A. bind_rows() 함수를 사용하자.
전체 cereal 데이터프레임에서 일부만 따로 떼어 두 개의 데이터 셋을 만들었다.
r1 <- cereal[1:5, 1:4] # 1:5행, 1:4열
r2 <- cereal[6:10, c(1:3, 5)] # 6:10행, 1:3열과 5열| |
|
r1과 r2를 생성하고 r1에는 calories가, r2에는 protein이 공통 변수가 아니다.
이 r1과 r2 데이터프레임을 bind_rows() 함수를 사용하여 병합하면 공통 변수가 아닌 부분은 NA로 처리되고 행이 결합하는 것을 확인할 수 있다.
bind_rows(r1, r2)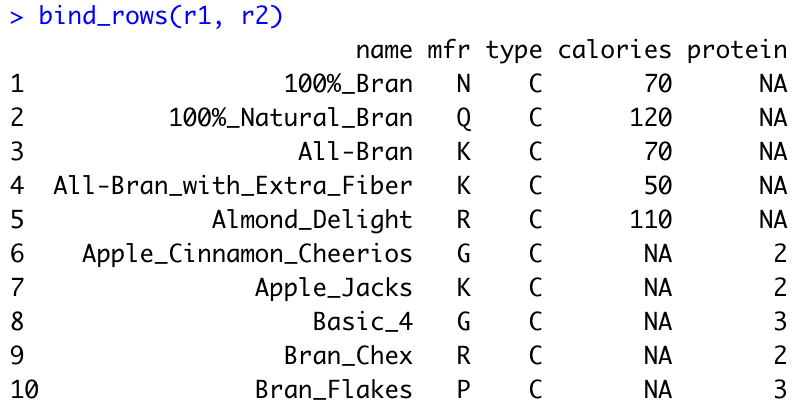
이 함수는 따로 연습문제는 없다.
지금까지 dplyr 패키지에서 중요한 함수들을 다뤄보았고, 경우에 따라서 반드시 사용하지는 않더라도 알고 있어야 하는 부분이라서 몇 차례에 걸쳐 포스팅해 보았다.
※ 참고: 코드 예시는 해당 함수를 활용하기 위한 방법으로 제시한 것입니다. 따라서 다른 방법이 존재할 수 있습니다.
'[R] 연습' 카테고리의 다른 글
| [R] 데이터 정제하기 (이상값편) (0) | 2021.12.10 |
|---|---|
| [R] 데이터 정제하기 (결측치편) (0) | 2021.12.01 |
| [R] dplyr 패키지 활용하기 (3편) (0) | 2021.11.29 |
| [R] 빅데이터 분석기사 예시 문제로 연습하기 (0) | 2021.11.28 |
| [R] dplyr 패키지 활용하기 (2편) (0) | 2021.11.27 |