지난 포스팅에서 다루었던 내용은
1) 데이터프레임에서 특정 조건에 맞는 행을 추출하고 싶다면 filter()함수를 사용하자.
2) 데이터프레임에서 특정 열만 추출하고 싶다면 select()함수를 사용하자.
이번 포스팅에서는 정렬과 파생 변수를 추가해보는 연습을 할 것이다. 또한 지난 내용을 활용한 코드를 연습할 생각이다.
# 참고로 mpg 데이터를 불러오기 위해서는 ggplot2 패키지의 설치가 필요하다.
# mpg.df <- as.data.frame(ggplot2::mpg)

Q. 데이터프레임에서 오름차순(작은 → 큰) 정렬을 하고 싶다면?
A. arrange() 함수를 사용하자.
Q. 그렇다면 내림차순(큰 → 작은) 정렬을 하고 싶다면 어떻게 할까?
A. arrange(desc()) 함수를 사용하자.
사용법은 간단하다.
만약 배기량(displ)이 적은 차부터 많은 차 순서대로 정렬하고 싶다면(오름차순), 다음과 같이 작성하면 된다.
mpg.df %>% arrange(displ)
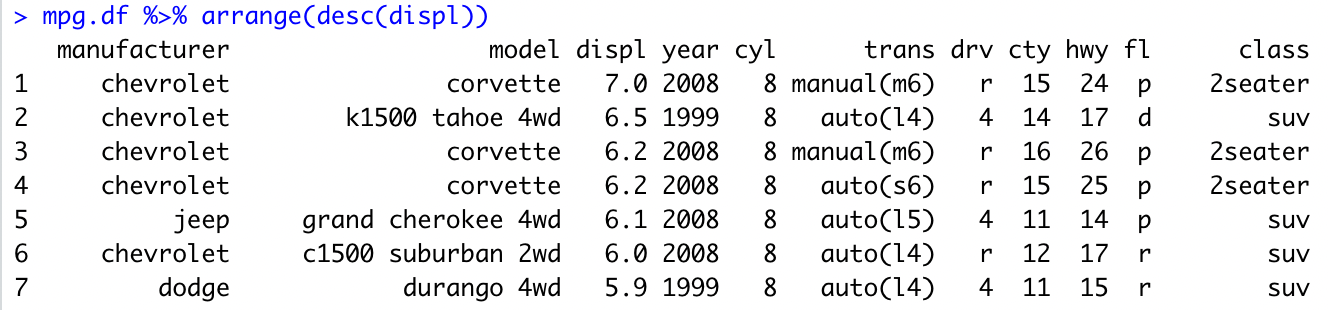
배기량(displ)이 많은 차에서 적은 순으로 정렬하고 싶다면(내림차순), 다음과 같이 작성하자.
mpg.df %>% arrange(desc(displ))
★ 예시문제 1)
제조사(manufacturer)가 "chevrolet"인 자동차 중에서 고속도로 연비(hwy)가 높은 자동차 10개의 정보를 출력하시오.
예시답안)
mpg.df %>% filter(manufacturer == "chevrolet") %>% arrange(desc(hwy)) %>% head(10)
# 지난 포스팅에서 연습했던 filter()와 함께 사용할 수 있다.
Q. 데이터프레임에 새로운 변수를 만들어 추가하고 싶다면 어떻게 해요?
A. mutate() 함수를 사용하자.
기존 데이터프레임에서 도시 연비(cty)와 고속도로 연비(hwy)를 더한 새로운 변수를 데이터프레임에 추가하고 싶다면, 다음과 같이 작성하면 된다.
mpg.df <- mpg.df %>% mutate(sum = cty + hwy)

★ 예시문제2)
mpg.df 데이터에서 제조사(manufacturer), 배기량(displ), 도시 연비(cty), 고속도로 연비(hwy) 변수만 따로 임의의 데이터프레임으로 생성한 후, 해당 데이터프레임에서 각 자동차의 도시 연비(cty)와 고속도로 연비(hwy)의 평균을 구한 값을 "avg" 새로운 변수로 추가하시오.
예시답안)
mpg.df2 <- mpg.df %>% select(manufacturer, displ, cty, hwy) %>% mutate(avg = (cty + hwy) / 2)
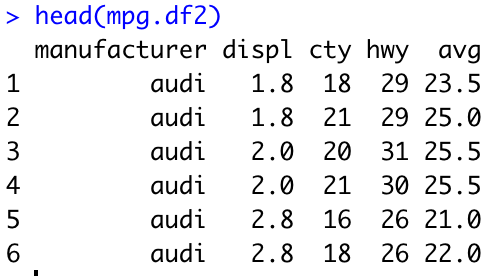
# 지난 포스팅에서 다루었던 select() 함수로 지정된 변수만 추출할 수 있고, mutate()를 활용하면 avg 파생변수를 생성할 수 있다.
※ 참고: 코드 예시는 해당 함수를 활용하기 위한 방법으로 제시한 것입니다. 따라서 다른 방법이 존재할 수 있습니다.
'[R] 연습' 카테고리의 다른 글
| [R] 데이터 정제하기 (결측치편) (0) | 2021.12.01 |
|---|---|
| [R] dplyr 패키지 활용하기 (4편) (0) | 2021.11.30 |
| [R] dplyr 패키지 활용하기 (3편) (0) | 2021.11.29 |
| [R] 빅데이터 분석기사 예시 문제로 연습하기 (0) | 2021.11.28 |
| [R] dplyr 패키지 활용하기 (1편) (1) | 2021.11.26 |